把网页作为数据来源
如何找到只在网络上存在的事物?不管你要找电邮地址、网址、图片或是维基百科条目,在本章你都可以了解到相关的工具可它们背后的故事。
网页工具
首先,你需要了解一些探索一整个网站而不是几个页面的服务。
- Whois
-
如果你访问whois.domaintools.com(或在Mac上的Terminal应用中输入whois www.example.com),你就可以得到任意网站的基本注册信息。近年来,很多网站所有者在注册域名时选择“隐私保护”模式,将注册信息隐藏。但大多数情况下你还是能够查到域名注册者的姓名、住址、电邮地址和电话号码。同时,你也可以输入数字型的IP地址,查找拥有该IP的服务器所属的组织或个人。在追查散播侮辱性言论和恶意攻击的用户时,这些服务特别方便,因为大多数网站都会记录访问者的IP地址。
- Blekko
-
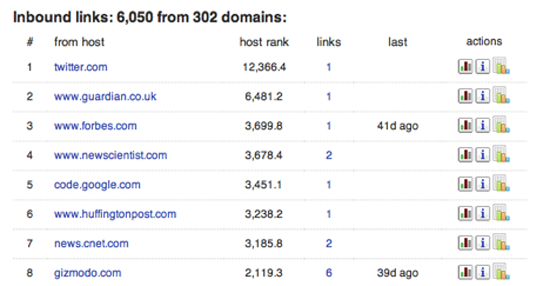
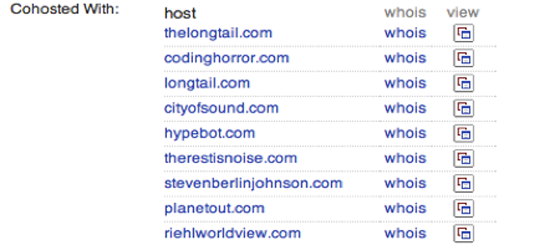
搜索引擎Blekko在抓取网页时使用了不常用的技术获得更核心的统计数据。在域名后输入“/seo”即可获得该URL包含的信息。 Figure 7网页的第一个标签按人气将链入该域名的网站进行了排序。这对于获知网站的覆盖面范围有多大极有帮助,由于Blekko使用了进站地址作为排序依据,部分网站的排名会比他们的Google排名更高。Figure 8展示了与该网站位于同一主机的其他网站域名。诈骗和垃圾网站常常会在同一个主机上建多个网站,在他们之间互相引用和链接,形成人气的假象。这些网站看起来都是各自独立的,甚至连注册信息都截然不同,但他们经常因为节省成本的原因架设在一个主机上。这些数据可以让你了解所搜索的网站背后的商业架构。
- Compete.com
-
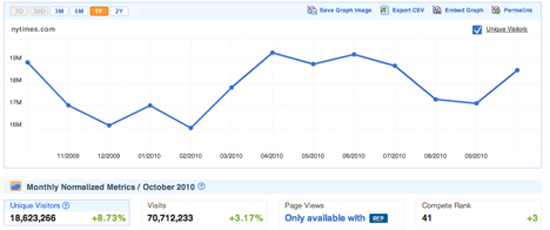
compete.com通过对美国网民的调查,为大多数网站提供细节化的用户数据,其中一些基本的数据是免费开放的。选择“站点信息”标签后输入域名(Figure 9),就可得到该站点在过去一年的流量,以及用户的访问数量及频率(Figure 10)。由于这些数据是基于调查所得,所以有些模糊,不过我通过将此数据与网站内部分析数据对比发现,他们还是相当准确的。在比较两家网站方面,这是相当好的数据来源,尽管双方的数据都不太精确,但仍能准确反映两者相对的人气状况。由于只对美国网民进行调查,Compete.com在对面向国际用户的网站支持上很弱。
- Google的站点搜索
-
使用“site:”参数搜索特定域名下的内容是个好方法。在关键词后加入“site:example.com”搜索,Google会仅展示指定域名下的内容。你还可以将范围进一步缩小的域名下的目录,比如“site:example.com/pages/”,获得更精细的结果。有时域名所有者发布的一些信息并没有刻意去展示,使用正确的关键词可以有效发掘出这些内容。
网页、图片和视频
有时你并没有对整个网站产生兴致,或许只关心特定事件的相关消息。以下的工具将展示网民在网上阅读、反馈、复制和分享内容的不同视角。
- Bit.ly
-
在分析用户分享特定链接的行为时,我总是会用Bit.ly。在网站上输入需要查询的网址,然后点击“信息页+”链接,便可得到完整的数据统计页面(首次使用时需要选择“整合Bit.ly链接”)。你会从中了解该页面的人气情况,包括在Facebook和Twitter上的热度,在下方还会呈现由backtype.com生成的用户关于该网页的公开对话。我发现在试图了解一个网站或网页为何如此热门时,这种流量和对话的组合统计十分有帮助,还可以精确定位目标人群。例如,它让我了解到主流对草根分享和莎拉•佩林的认识都是错的。
- 推特
-
随着越来越多的人开始使用微博客服务,微博已成为衡量用户对特定内容分享和交流的实用工具。操作起来十分简单,你只需将网址放入搜索框,也许还需要在搜索结果页面上点一下“更多推文”获得所有结果。
- Google网页快照
-
网站发布者在发现页面内容有争议时,可能会将其删除或是在不做任何通知的情况下进行修正。如果你怀疑自己遇到了这种情况,首先就应当看看Google对该页生成的上一次快照。由于Google抓取网页的频率越来越高,这要求你必须在发现情况可疑后的几小时内就进行快照查询。在搜索框中输入要查询的网址,然后在结果页上点击向右的箭头,即可看到页面预览。运气好的话,预览结果上方会有“网页快照”链接,点击即可获得Google对该网页的存档结果。如果网页加载缓慢,你可以试试页面最上方的“纯文本”选项获得更简洁的页面。打开快照后,你最好进行截屏,或者把相关的信息复制下来,因为随着Google的下一次页面抓取,这一结果可能在任何时刻被覆盖。
- 互联网档案馆的时间机器
-
你也许会需要特定页面在过去数年、数月间的长期改动情况,互联网档案馆的时间机器服务可以帮你,它会定时对人气最高的页面进行截图。访问网站,输入需要查找的网页地址,如果有存档的话,页面上就会显示出带有链接的日历,接下来选择具体日期即可查看。时间机器服务将展示该网页在当时的大致情形,其中的版式和图片可能已经失效,但通常这对于理解网页内容没什么影响。
- 查看源代码
-
这可能会花点时间,但开发者的确经常在网页的HTML代码中留下评论或者其他线索。不同的浏览器有不同的菜单设置,但你总能找到“查看源代码”获得原始HTML的选项。你不需要理解其中的机器语言,只需要找寻散落在其中的文本内容。即使代码中只提到过版权声明和作者的名字,这通常也成为了解页面创建过程和目的的重要线索。
- TinEye
-
有时网络上的图片没有标注来源,传统的搜索引擎功能没什么用,但你又需要知道它的来源。TinEye提供了一种特别的“反向图片搜索”功能,提交图片后它就会在网络上中找出相似的图片。TinEye使用了图像识别技术,对于被裁减、失真和压缩的图片也很有很好效果。当你怀疑某图片被裁减过用来伪造原创作品或是曲解原意时,这个功能可以帮你找到原始来源。
- YouTube
-
点击每个视频右下方的“统计”按钮就可得到观看者的详细信息。尽管数据有些笼统,但其对于了解观看者的所在地和观看时间很有帮助。
电子邮件
在研究电子邮件时,你经常想了解发件人的具体身份和位置。虽然没有现成的工具完成这项供需,但了解一些所有电邮中有的隐藏报头十分有帮助。报头类似邮戳,可以揭示发件人数量惊人的信息。尤其是,它往往包含了电邮发送时使用机器的IP地址,这类似于电话中的来电号码。接下来,你可以对该IP地址进行whois查询,得到其所属的组织。如果得到Comcase或AT&T之类向消费者提供网络的服务商,则可去MaxMind查询该IP的大致位置。
在Gmail中查看邮件报头,打开信件后,展开上方“回复”按钮右侧的下拉菜单,选择“显示原始邮件”,然后在新窗口就会展示信件的隐藏信息了。
代码最上方会有十几行以冒号结尾的参数,你所需要的IP地址就在其中某行。表示IP的参数多种多样,如果发件人使用Hotmail,则该行显示+X-Originating-IP:+,而Outlook和Yahoo的信件会在首行标记+Received:+。
查询该IP我得知其属于英国的一家名为“Virgin Media”的ISP,然后我通过MaxMind定位服务得知其来自我的家乡——剑桥。这意味着我可以充分确信发件人的确是我的父母,而不是诈骗犯。
流量趋势
如果你需要调查一个很广泛的话题,而不是特定的网站或事物,那你需要这些让你洞察细节的工具:
- 维基百科条目流量
-
如果你对公众对特定话题或人物的热度变化有兴趣,可以在stats.grok.se查看维基百科任意页面每日的访问量。网站页面略显错草,但它可以让你深度挖掘所需信息。输入你感兴趣的事物就可得到该页面一个月以来的流量情况。图表会显示指定月份中每日的访问量。不过你每次只能选一个月的数据查看,这要求你多次选择才能得到更长时期的数据。
- Google Insights
-
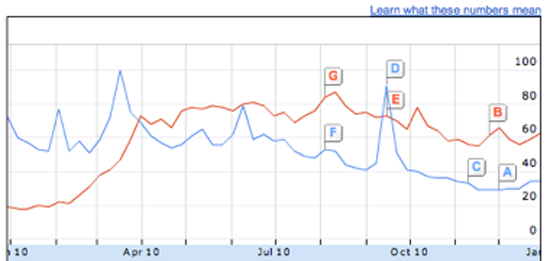
使用Google Insight(Figure 11)可以帮助你了解公众的搜索习惯。输入一对热门关键词,比如“Justin Bieber vs Lady Gaga”,就可以得到两人搜索数据随时间变化的关系图标。Google还提供多种选项提炼数据,可以限定地理位置和时间参数。此服务唯一的劣势是其只提供搜索数据的相对关系,而不提供绝对值,在转换数据时会有困难。
— _皮特·沃登(Pete Warden),独立数据分析师、开发者_