使用数据可视化洞察数据
可视化对数据分析至关重要。它是进行数据分析的第一个战场,可以揭示出数据内在的错综复杂的关系,在这一点上可视化的优势是其它方法无可比拟。“我们寻找意想不到的发现,我们挑战料想之中的观点。”
— 威廉·克利夫兰(William S. Cleveland)
数据本身是不可见的,它们以比特和字节的形式存储在计算机硬盘驱动器的某个文件里。为了能让数据的意义得以体现,我们需要将其进行可视化。在这一章里,我将采用广义的_可视化_概念,包括用纯文本展示的数据。例如,把一个数据集加载到某个电子表格软件里,这一过程就可以被认为是数据的可视化。看不见的数据瞬间就变成了屏幕上看得见的“图像”。因此,我们要探讨的问题不是新闻记者需不需要对数据进行可视化处理,而是在何种情况下用何种可视化方法,能够让数据分析达到最佳的效果。
换句话说,什么时候需要采用除表格以外的方式来进行数据的可视化呈现呢?答案很简单:_几乎任何时候_。仅仅使用表格肯定不足以让我们得到对数据集的整体把握。而且,光用表格也不能帮我们直接识别出数据的内在模式。一个最常见的例子就是,与地理位置相关的这一类型的数据,只有当数据在地图上被可视化之后,其具有的特点才能显现出来。然而,除此之外,还有很多其他的模式,我们将在本章的后面看到。
利用可视化进行数据发掘
想要通过可视化工具和技术从数据集中找到一大堆的现成新闻报道,这种想法是不现实的。在数据可视化分析中,没有任何的技术或方法,可以保证你一定能找到数据背后隐藏的故事。相反,通过对数据进行挖掘,洞察数据背后隐藏的秘密对新闻记者来说反而更有用。借此,优秀的新闻记者会将这些数据和洞察巧妙的编织到新闻报道当中。
每一种新的可视化方法都可能会为我们揭示数据的一些新的意义。在这其中,某些可能已经被人们所熟知(但是,可能尚未被证实);而某些又可能是闻所未闻,甚至让人大吃一惊;一些新的洞见可能会开启一个新闻报道;而其他的可能仅仅是错误数据的结果,所有这些都很可能通过数据可视化来发现。
下面的流程Figure 4对于更有效的进行数据挖掘很有效:
学习如何进行数据可视化
可视化为数据集提供了一个独特的视角,进行数据可视化的方法有很多种。
对于处理相对简单的维度的数据,表格的功能是非常强大的。表格可以以最为结构化和组织化的方式显示数据标签和数量,而且结合排序和筛选可以让其功能得到最大程度的发挥。此外,爱德华·塔夫特(Edward Tufte)建议在表格中添加一些小的数据图,例如在每一行加一个柱状图,或者画一个小的线形图(后来也被称为迷你图)。但是,正如在简介中所提到的,表格无疑有其局限性。表格可以轻松帮你找到一维数据的异常值,比如排名前10的数据;但当要同时比较多维数据时(例如每个国家的人口随时间的变化),用表格就力不从心了。
一般来说,数据图可以让你把数据的不同维度通过几何形状表现出来。关于每种视觉效果的功能可以说上很多,但简单来说就是:颜色不太好用,位置决定一切。比如,在散点图中,数据的两个维度映射到散点图的x轴和y轴。通过改变图标的颜色或大小,你还可以显示出第三个维度的数据。线形图特别适用于显示数据随时间的演变,而柱形图可以很好的用来比较分类数据。你还可以把图表元素相互堆在一起。如果你想比较少数几个组别的数据,那么,用同一类型数据图表示多个实例是一种强大的方法(也称为网格图)。在各种数据图中,你可以使用不同的刻度去发掘数据不同方面的信息(例如使用线性或对数刻度)。
事实上,我们处理的大多数据,都以某种方式与现实大众有所联系。地图的作用就是重新建立数据与我们的物理世界之间的联系。想象一个犯罪事件的地理分布数据集,这其中你最想知道的就是犯罪发生的_地点_,而数据地图可以揭示数据中地理位置的关系,例如从北部到南部,或者从城市到农村地区的趋势。
说到关联,第四种最重要的可视化类型就是网络图谱。网络图谱的功能就是显示数据点(节点)之间的相互联系(边)。节点的位置可以通过简单或复杂的图形布局算法计算得到,使我们能够直观的看到网络内部的结构。一般来说,使用网络图谱进行可视化时,需要注意的是要找到一种合适的方式来对网络本身进行建模。并不是所有的数据集都包含内在联系,即使有,可能也不是数据最有意思的地方。某些时候,节点之间的联系是由新闻记者来定义的。一个完美的例子就是美国参议院的社交网络图,网络的边用于连接相同投票超过65%的参议员。
对结果进行分析和解释
对数据进行了可视化之后,下一步就是要研究你所创建的数据图。你可以这样问自己:
-
我可以从这幅图片里看出什么?这是我想要的吗?
-
有什么有趣的模式?
-
在其语境中,它有什么意义?
有的时候,你最后可能会发现,虽然做出来的图非常漂亮,但好像不能提供给你任何有趣的东西。不过,即使没什么价值,你都能够从可视化结果中发现_一些东西_。
记录你的分析步骤和洞察结果
如果把可视化分析看作一段在数据集中的旅程,那么对数据分析过程的记录就是你的旅行日记。它会告诉你到过哪些地方,看见了怎样的景色,以及你如何作出的下一步决定。你甚至可以在看到数据之前,就开始你的记录。
大多数情况下,在开始分析一个未曾见过的数据集之前,我们的头脑中就已经充满了关于它的预想和假设。我们对手头的数据集感兴趣,通常是有原因的。记录下最初的想法是个聪明的做法。通过对预想的记录可以可以帮助我们识别偏见,降低误读的风险。
我坚持认为记录是这个流程中最重要的一步,而它也是我们最容易忽略跳过的一步。在下面你将要看到的例子中,我所描述的流程中涉及了大量的作图和数据加工。看着一组15张你做的图,你可能会摸不着头脑,特别是经过一段时间之后。实际上,这些图只有呈现在其产生的语境中才是有价值的(对你或其他你想要与之分享你的发现的人)。因此,你应该花时间做些这样的笔记:
-
我为什么要做这个图?
-
为了做这张图,我对数据做了哪些处理?
-
这张图想表达什么意思?
转换数据
自然地,带着从上一步可视化处理中收获的洞察,你可能对下一步想看到什么有了想法。可能你已经在数据集中发现了一些有趣的模式,那么,现在你想要对其进行更细致的分析。
可以进行的数据转换包括:
- 缩放
-
能够看可视化图中某一特定部分的细节
- 汇总
-
将多个数据点合并到一个组
- 过滤
-
(暂时性的)移除不是主要关注对象的数据点。
- 去除异常值
-
排除异于99%数据的的单个的数据点。
让我们想象一下你所得到的可视化图表,其中能看到的只是一堆杂乱无章的点和成百上千的连线(在可视化所谓的密集连接网络中经常出现这种情况),一个常用的转换步骤是过滤掉某些连线。例如,如果一些边代表捐助国向受援国方向的资金流动,我们可以去掉低于某一金额的资金流动的数据。
使用什么工具
选择恰当的数据可视化工具并不是一件容易的事。每一种数据可视化工具都有其擅长的地方。可视化和数据加工应当是简单和高效的。如果你需要几个小时来调整参数,你就不会作出太多的尝试。这并不是说你不需要学习如何使用工具。不过一旦你学会了,它就应该是非常高效的。
通常,选择一个可以兼顾数据加工和数据可视化的工具是很有必要的。把任务分散在不同的工具中意味着你不得不把数据导来导去。下面简短列出了一些数据可视化和数据处理的工具:
-
电子表格,如LibreOffice、Excel或Google文档。
-
统计编程架构,如R(r-project.org)或Pandas(pandas.pydata.org)
-
地理信息系统(GIS),如Quantum GIS、ArcGIS和GRASS
-
可视化程序包,如d3.js(mbostock.github.com/d3)、Prefuse(prefuse.org)和Flare(flare.prefuse.org)
-
数据加工工具,如Google Refine、Datawrangler
-
非编程可视化软件,如ManyEyes和Tableau Public(tableausoftware.com/products/public)
下一节中的可视化实例就是用R语言创建的,它是(科学)数据可视化的利器。
可视化实例:感知美国总统大选捐款数据
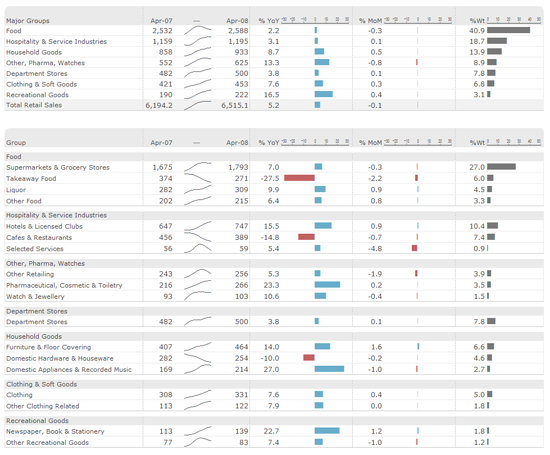
让我们来看看美国总统竞选财务数据库,其中包含约45万笔捐给各个总统候选人的款项。 这份数据保存在60兆大小的一个CSV文件里,用Excel这样的程序处理这么大的数据是非常吃力的。
首先,我会明确地写下对联邦选举委员会捐款数据的初步猜测:
-
奥巴马应该会得到最多的捐款,(因为他是现任总统且人气最高)。
-
随着选举日临近,捐款数目增加。
-
奥巴马比共和党候选人获得更多的小额捐款。
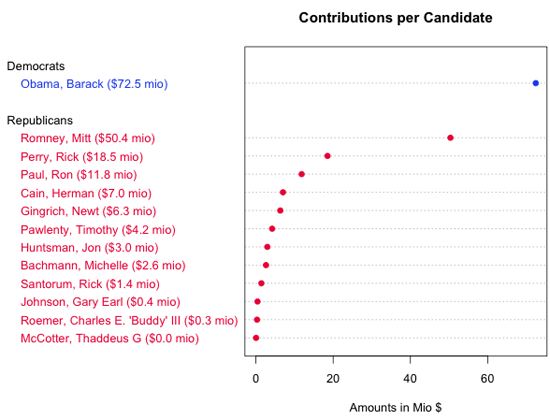
要回答第一个问题,需要对数据做些_转换_。我们不能只看每笔单独的捐款,而需要把每位候选人收到的捐款总金额算出来。在用分类汇总表对结果进行_可视化_后,可以确认我们的假设是正确的,奥巴马确实收到了最多的捐款:
| 候选人 | 金额 ($) |
|---|---|
奥巴马, 巴拉克 |
72,453,620.39 |
罗姆尼, 米特 |
50,372,334.87 |
佩里, 里特 |
18,529,490.47 |
保罗, 荣恩 |
11,844,361.96 |
凯恩, 赫尔曼 |
7,010,445.99 |
金里奇, 纽特 |
6,311,193.03 |
波伦提, 提摩西 |
4,202,769.03 |
亨斯迈, 乔恩 |
2,955,726.98 |
巴赫曼, 米歇尔 |
2,607,916.06 |
桑托伦, 里特 |
1,413,552.45 |
约翰逊, 加里·厄尔 |
413,276.89 |
罗默,查尔斯·E·布迪三世 |
291,218.80 |
麦克寇特,赛迪斯 |
37,030.00 |
虽然从这个表能看出候选人收到捐款的最大值、最小值和排序情况,但它并没有揭示候选人排名的潜在模式。Figure 7是这份数据的另一种可视化,被称为“点状图”,从中我们可以看出表格所呈现的所有信息,以及数据的内在模式。例如,在点状图里我们不需要做减法运算,就可以直接比较奥巴马与罗姆尼或者罗姆尼与佩里之间的差距。(注:这张图由R语言创建,你可以在本章末尾找到源代码的链接)。
现在,让我们接着做一张更大的图。首先,我用一个简单的散点图_显示_捐款金额随时间的变化情况。可以看到,有三个巨大的离群值,跟它相比其他捐款都微乎其微。进一步调查发现,这些巨额捐款都来自“奥巴马胜利基金2012”(又名超级PAC),该基金分别在去年6月29日捐款45万美元, 9月29日捐款150万美元, 12月30日捐款190万美元。
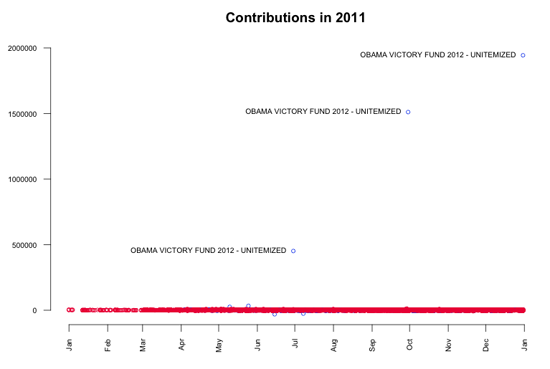
超级PAC(政治行动委员会)的巨额捐款无疑是这一数据最大的发现,但除此以外可能还有其他有意思的地方。现在的问题是,这些巨额捐款会影响我们对来自个人的小额捐款的分析,所以要把它们从数据中剔除出去。这种转换通常称为去除离群值。再次进行可视化,可以看到,大多数捐款都在5千到1万美元的范围内。
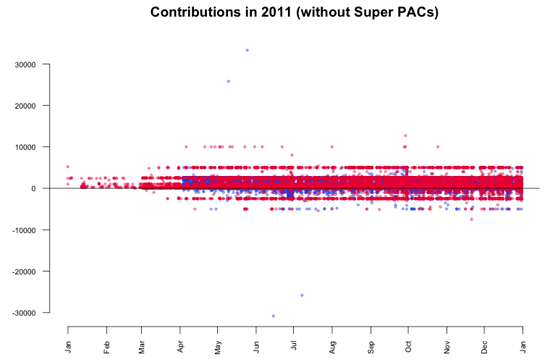
根据联邦竞选法对个人捐款所设置的限制,每位候选人不允许接受超过2500美元的个人捐款。但我们从图中看到,很多捐款都超出了这一限额。特别是五月的两笔大额捐款引起了我们的注意。它们看起来与六月和七月的负数金额(退款)相对应。进一步的数据调查,发现了以下交易:
-
受聘于班纳克事务所(律师)来自旧金山的斯蒂芬·詹姆斯·戴维斯,在5月10日向奥巴马捐款$25,800。
-
受聘于墨菲集团(公共关系)来自小石城的辛西娅·墨菲,在5月25日奥巴马捐款$33,300。
-
6月15日,$30,800被退还给辛西娅·墨菲,其中扣除了$2500的捐款。
-
7月8日,$25,800被退还给斯蒂芬·詹姆斯·戴维斯,其中并没有扣除任何捐款。
这些数字有什么特别的意义吗?退还给辛西娅·墨菲的30,800美元,等于每年个人向全国各政党委员会捐款的最高金额。或许她只是想把给总统选举的钱和给民主党的一次捐了,但最后被拒了。而退还斯蒂芬·詹姆斯·戴维斯的25,800美元等于30,800减去5000美元,而5000美元是个人向其他政党委员会捐款的限额。
上一张图里另一个有趣的发现,就是可以看到向共和党候选人的捐款分别在5000美元和-2500美元有一条水平线。为了看得更清楚,我单独把共和党的捐款可视化。如果不进行可视化,是不可能发现这些内在的模式的,这里做出来的数据图也是对此最好的佐证。这些图是数据内在模式的完美实例,没有数据可视化,它们是不可能被发现的。
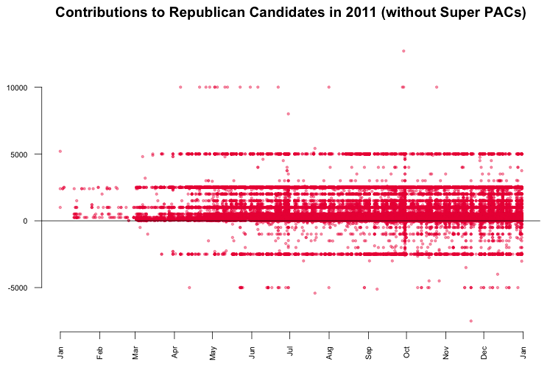
我们可以看到,向共和党候选人捐款的数值主要集中在5000美元,但实际去看一下数据你会发现,这样的捐款有1243笔,只占捐款总笔数的有0.3%,但因为其他的捐款数额随时间分布比较均匀,所以在这里才能看出这条线。有意思的是,个人的捐款限额是2500美元。因此,超过额度的捐款会退还给捐助者,这就是为什么在-2500美元的位置出现了第二条线。相反,对奥巴马的捐助没有呈现类似的情况。
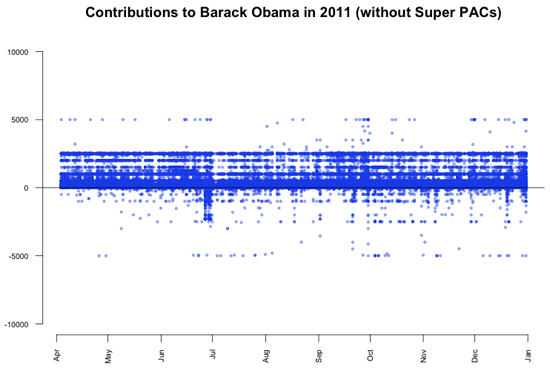
接下来,就来看看为什么数以千计的共和党捐助者都没注意到个人捐款限额这件事。可能会非常有趣。为了进一步分析这个议题,我们看看各位候选人获得的5000美元捐款的总笔数。
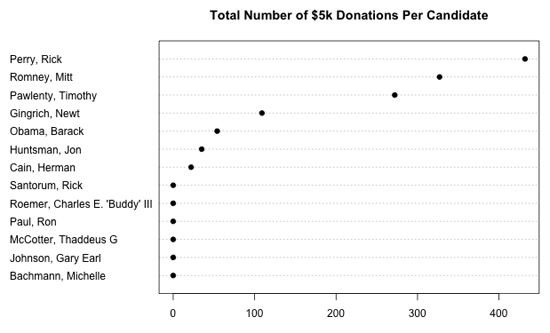
当然,这是一幅被曲解的图因为它没有考虑各候选人收到的捐款总额。下图显示每位侯选人收到的超过5000美元的捐款在总捐款笔数中的比例。
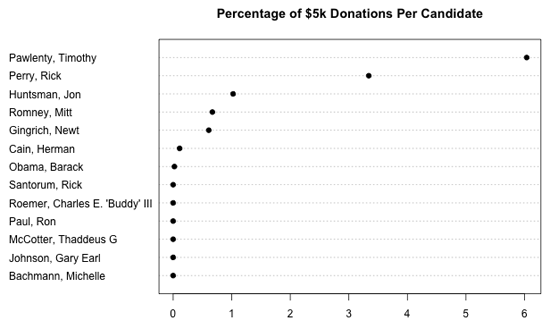
我们能从中学到什么
这样一个对未知数据集进行可视化分析的过程,常常让人感觉像在一个陌生的国度进行一次令人兴奋的旅行。你凭借仅有的数据和一些假想,就像一个外国人一样开始,,但每进行一步,每做出一张图表,你都会获得有关这个议题的新的洞察。基于这些洞察,你再确定下一步的分析方向,以及数据的哪些方面值得去深入研究。正如你在这一章所看到的,这种数据可视化、分析以及转换的过程几乎可以无限重复下去。
获得源代码
本章中的所有图表都是通过美妙而强大的R语言绘制的。R语言主要用作科学的可视化工具,它几乎可以实现任何已有的可视化或者数据加工方法。如果你对利用R来进行可视化或数据加工感兴趣,下面是绘制本章图表所用的源代码。此外,还有种类繁多的书籍和教程可供选择。 dotch
还有种类繁多的书籍和教程可供选择。
— 格雷格·艾许(Gregor Aisch),开放知识基金会